
안녕하세요! AI쌤입니다.
오늘은 인공지능이 세상을 어떻게 인식하고, 우리 일상에서 어떻게 활용되는지, 그리고 컴퓨터 비전이 가진 한계까지 아주 쉽게 풀어서 이야기해볼게요. 인공지능이란 게 사실은 생각보다 우리 가까이에 있고, 우리가 상상하는 것보다 훨씬 다양한 방식으로 세상을 보고 있답니다.
1. 인공지능은 세상을 어떻게 볼까? – 센서 이야기
먼저, 인공지능이 세상을 인식하는 데 가장 중요한 건 바로 센서예요. 센서는 인간의 오감(눈, 귀, 피부 등)을 흉내 내는 기계 장치라고 생각하면 됩니다.
- 카메라 센서는 우리의 눈처럼 빛을 받아 이미지를 만듭니다.
- 사운드 센서는 소리를 전기 신호로 바꿔서 컴퓨터가 들을 수 있게 해줘요.
- 압력 센서는 촉각, 온도 센서는 온도, 습도 센서는 습도, 바이오센서는 맛, 가스 감지 센서는 냄새를 감지합니다.
이 센서들이 받아들인 정보는 아날로그(연속적인 신호) 형태인데, 이걸 컴퓨터가 이해할 수 있도록 디지털(0과 1) 신호로 바꿔주는 과정이 필요해요. 이 과정을 A/D 변환이라고 해요.
예를 들어, 스마트홈에서는 온도 센서가 집 안 온도를 측정해서 에어컨이나 난방기를 자동으로 켜고 끄기도 하고, 동작 센서로 사람이 방을 나가면 불을 자동으로 꺼주는 식이죠.
2. 인식의 과정 – 사람과 인공지능의 차이
인간이 친구의 표정, 목소리, 행동을 보며 감정을 파악하듯, 인공지능도 센서로 정보를 받아서 특징을 뽑아내고, 학습한 정보와 비교해 판단합니다.
예를 들어, 모나리자 그림의 감정을 인공지능이 분석한다면, 먼저 얼굴을 찾아내고, 눈, 입, 이마 같은 특징을 추출해서 미리 학습한 감정 데이터와 비교해 ‘기쁨’, ‘중립’, ‘경멸’ 같은 감정을 추정하는 식이에요.
3. 인공지능의 실생활 활용 – 무인 상점과 자율주행차
무인 상점
- 고객이 매장에 들어오면 QR코드로 신원을 확인하고,
- 카메라와 무게 센서로 어떤 물건을 집었는지, 다시 내려놨는지 실시간으로 파악해요.
- 계산대에 가지 않아도 자동으로 결제가 이루어지죠.
자율주행 자동차

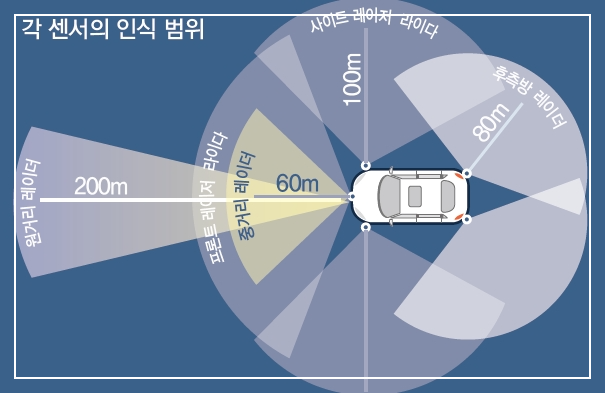
- 자동차에는 라이다(레이저), 레이더(전파), 카메라 등 다양한 센서가 달려 있습니다.
- 이 센서들이 도로의 신호등, 보행자, 다른 자동차, 표지판 등 다양한 정보를 실시간으로 인식해요.
- 센서가 모은 정보를 인공지능이 분석해서 스스로 운전하고, 위험 상황도 감지해 대처합니다.
하지만! 아직 센서에만 의존하기엔 한계가 있어요. 예를 들어, 카메라 센서가 흙탕물에 더럽혀지면 마치 사람이 눈을 가린 채 운전하는 것처럼 위험해질 수 있어요. 또, 센서가 하늘과 흰색 트럭을 헷갈려서 사고가 난 사례도 있습니다. 그리고 센서의 인식 범위가 한정적이어서, 고속도로에서 빠르게 달릴 때는 충분히 멀리까지 인식하지 못할 수도 있어요.

4. 컴퓨터 비전이란? – 컴퓨터의 ‘눈’
컴퓨터 비전은 컴퓨터가 인간처럼 이미지를 보고, 그 안에서 의미 있는 정보를 찾아내는 기술이에요.
- 객체 탐지(Object Detection) : 사진이나 영상에서 ‘무엇이 어디에 있는지’ 찾는 기술. 예를 들어, 자율주행차가 보행자, 차선, 표지판을 찾아내는 것.

- 이미지 분할(Image Segmentation) : 이미지의 모든 픽셀을 각각 어떤 사물에 속하는지 구분하는 기술. 의료 영상에서 병변 부위를 정확하게 표시할 때 사용돼요.

- 이미지 분류(Image Classification) : 이미지 전체가 무엇인지를 판단하는 기술. 예를 들어, 사진 속 동물이 고양이인지, 강아지인지 구분하는 것.

실제로는 YOLO 같은 빠른 객체 탐지 모델이 영상 속에서 여러 사물을 실시간으로 찾아내고, COCO 데이터셋 같은 방대한 이미지 데이터로 인공지능이 많이 학습해서 성능을 높이고 있습니다.



5. 컴퓨터 비전의 한계 – 인간의 눈과 비교해보면?
여기서 중요한 점! 컴퓨터 비전은 인간의 시각만큼 완벽하지 않아요.
- 해상도와 처리 속도 :
인간의 눈은 아주 높은 해상도와 빠른 처리 속도를 가지고 있지만, 컴퓨터는 실시간으로 대용량 이미지를 처리할 때 메모리와 속도에 한계가 있어요.
- 직관과 맥락 이해 :
우리는 고양이와 비슷하게 생긴 아이스크림, 강아지와 닮은 머핀도 바로 구분하지만, 인공지능은 이런 걸 구분하려면 수많은 이미지를 학습해야 해요.
- 3차원 정보 처리 :
인간은 두 눈으로 거리와 깊이를 쉽게 파악하지만, 컴퓨터는 2D 이미지로부터 3D 정보를 추정하기 어렵기 때문에 다양한 센서를 결합해야 해요.
- 환경 변수와 적대적 공격 :
조명, 센서 오염, 배경 변화 등 환경이 조금만 달라져도 인식 오류가 생길 수 있습니다.
또, 적대적 공격(adversarial attack)이라는 것도 있는데, 예를 들어 판다 사진에 눈에 안 보이는 노이즈를 살짝 더하면 인공지능이 판다가 아니라 긴팔원숭이라고 잘못 인식하기도 해요.
심지어 STOP 표지판에 노이즈를 추가하면 ‘GO’로 인식해서 큰 사고로 이어질 수도 있죠.
6. 앞으로의 과제와 전망
이런 한계들을 극복하기 위해선
- 더 다양한 센서의 결합
- 더 많은 데이터와 정교한 학습
- 적대적 공격에 강한 기술
- 인간처럼 맥락과 감정, 의도까지 이해하는 기술
이 필요합니다.
그리고 인공지능의 언어 이해, 음성 인식 기술도 점점 발전하고 있어요. 챗봇, 음성비서, 기계 번역 등에서 이미 활발히 쓰이고 있죠. 하지만 인간처럼 ‘상식’, ‘감정’, ‘의도’까지 완벽하게 이해하려면 아직 갈 길이 멀어요.
마치며
정리하자면, 인공지능은 센서와 컴퓨터 비전, 음성 인식, 언어 이해 등 다양한 기술로 우리 생활 곳곳에 들어와 있지만, 인간의 직관과 융통성, 맥락 이해에는 아직 미치지 못합니다. 앞으로 기술이 더 발전하면, 인공지능은 더 똑똑해지고, 우리와 더 자연스럽게 소통하고, 더 안전하게 세상을 인식할 수 있게 될 거예요.
궁금한 점이나 더 알고 싶은 내용이 있으면 언제든 댓글로 남겨주세요!
'인공지능 이야기' 카테고리의 다른 글
| 당신의 얼굴 나이는 몇 살? AI 페이스에이지로 알아보자! (9) | 2025.05.10 |
|---|---|
| "사진만 올리면 끝! 당근마켓 AI 글쓰기 기능으로 중고거래가 더 쉬워졌어요" (9) | 2025.05.08 |
| "혹시 모르고 있는 인공지능 기술, 궁금증을 한 번에 해결!" (13) | 2025.05.07 |
| 프롬프트 잘 쓰는 법: ChatGPT를 200% 활용하는 프롬프트 작성 가이드 (14) | 2025.05.06 |
| 인공지능의 주요 기술, 일상에서 만나는 AI 혁신 사례 총정리 (28) | 2025.05.06 |



